

Refactoring Agents
What Building "Agentic AI" Teaches About Software and Workforce Design

Last week I analyzed 47 AI implementations and argued we’re in the middle of a Great Refactor—a systematic reassessment of which tasks belong to humans versus AI. This week, I want to show you what that refactor looks like in practice, because I’ve been living it in two contexts: building what vendors call “agentic AI” software, and watching organizations struggle with the “AI employee” concept.
The terminology problems playing out in both domains are structurally identical. More importantly, the solution is the same: rigorous threshold analysis about what to delegate and what requires accountability.
Whether you’re refactoring code or refactoring teams, the fundamental question doesn’t change: what crosses the threshold where a cognitive instrument is the right tool, and where must judgment and accountability remain? Let me show you what I mean.

Building Agents: The Discernus Experience
This summer I built Discernus, a platform for systematic rhetorical analysis. The use case: ingest a corpus of texts (political speeches, debate transcripts, party platform documents), apply pre-defined analytical frameworks for linguistic markers (populist rhetoric, civic virtue, nationalist tropes), extract structured data with supporting evidence, calculate derived metrics, run statistical analysis, and synthesize results into narrative reports.
I could have built this using traditional software patterns—parse the text with regex, extract features with rule-based logic, calculate statistics with deterministic code, template the output. That’s how I would have approached it three years ago. But text parsing with traditional software is inherently brittle. Edge cases proliferate. Exceptions need manual handling. The code becomes a maintenance nightmare.
Instead, I adopted what I started calling a “Thin Software” approach for my own design clarity: software handles orchestration and routing, but anything requiring interpretation or parsing gets delegated to an LLM. The orchestration/execution separation is standard architecture, but the decision boundary—when to use deterministic code versus statistical inference—felt new. Think of it as a postal service metaphor: software moves packages and manages logistics, but when you need to “open the mail and read it,” that goes to the cognitive instrument.
Discernus uses what vendors would call “agents” but which are better described as procedurally-contextualized LLM interactions. One agent validates that the experimental setup is coherent and complies with specifications. Another applies the analytical framework to each document and produces structured results. Another extracts those results and prepares them for statistical analysis. Another synthesizes findings into narrative reports. Another infuses the reports with direct quotes from source documents to support claims.
These agents aren’t “autonomous” in any meaningful sense. They’re procedurally contextualized—each uses the results of the previous step to inform the next operation. They follow defined workflows. They can’t make truly strategic decisions. They process at scale what I specify, using pattern recognition I can’t match, but they never deviate from the architecture I designed.
The iterative refinement was revealing. I had to learn through trial and error how much work each agent could handle before becoming overwhelmed. Context window limits mattered less than output token limits (a real Achilles heel for LLMs doing structured data extraction). Eventually I found the right grain size for each component—small enough to stay within token budgets, large enough to maintain coherent context.
One surprising thing plagued my project was that Cursor’s AI agents (trained on traditional software patterns) desperately wanted to write “Thick” code—lots of parsing logic, lots of conditional branches, lots of procedural complexity. I had to constantly intervene with explicit instructions to keep the codebase Thin. Even with draconian restrictions and audit steps, the pull toward traditional software patterns was strong.
That tension suggests something about the refactor playing out in software development right now—the long established patterns don’t quite fit, and the tooling hasn’t caught up to this shift in delegation economics.
The Software Refactor: When to Stay Thin
Traditional software architecture optimizes for deterministic logic. You define requirements, write code that implements those requirements exactly, test against specifications, and deploy when behavior is predictable and reproducible. This works beautifully for well-defined procedural problems.
But substantial categories of software problems don’t fit that paradigm cleanly. Anything involving natural language understanding, ambiguity resolution, fuzzy pattern matching, or context-dependent interpretation requires either massive edge-case handling or brittle rule systems that break constantly.
LLMs change the calculus. For tasks requiring interpretation or semantic understanding, delegation to a cognitive instrument often produces better results with less engineering complexity. The question becomes: when should you write logic versus when should you delegate to pattern recognition?

The threshold analysis from the Great Refactor applies directly:
Complexity threshold: When the number of edge cases or conditional branches exceeds what you can realistically maintain, consider whether a well-prompted LLM handles the variability better than exhaustive code.
Semantic interpretation: When the task requires processing natural language meaning, context, or intent rather than matching exact patterns, the cognitive instrument likely outperforms regex and parsers—not because it truly “understands,” but because statistical pattern recognition over language handles ambiguity better than rule-based systems.
Maintenance burden: When you’re spending more time handling exceptions than building features, you’ve probably crossed the threshold where Thin Software becomes more sustainable.
Discernus would have been genuinely impossible to build with traditional approaches in the time and budget I had available. The framework validation alone—checking whether an analytical rubric is internally coherent and properly specified—would have required extensive rule-based logic that breaks as soon as users deviate from expected formats. Delegating that validation to an LLM with clear instructions about what constitutes coherence worked dramatically better.
The cost was real—over $1000 in API expenses last summer—but that enabled capabilities that simply didn’t exist in any software stack a few years ago. The tradeoff analysis increasingly favors delegation when the alternative is either massive engineering effort or accepting brittleness.
But here’s what this doesn’t mean: The LLMs in Discernus aren’t “agents” in the sense that vendors market them. They’re cognitive instruments wrapped in procedural code. They don’t make autonomous decisions. They don’t “understand” the research domain. They apply statistical pattern recognition to tasks I carefully scoped and constrained. The power comes from knowing precisely what to delegate versus what stays in deterministic logic.
When I read vendor marketing about “AI agents that work autonomously” and “digital workers that understand your business,” I recognize the systems they’re describing—I’ve built them. But the framing is dangerously wrong. These aren’t autonomous agents with judgment. They’re sophisticated pattern matchers wrapped in orchestration code. That distinction determines whether your software succeeds or falls into the deterministic software trap I described in my last post.
The real insight for software teams: you’re going to refactor around cognitive instruments whether you call them “agents” or not. The question is whether you understand when to stay Thin (delegate to the instrument) versus when to stay Thick (keep it in deterministic code). That boundary determines your architecture’s sustainability.
The Workforce Refactor: Beyond “AI Employees”
The same refactor is playing out with human work, but the terminology problems are causing more damage because the stakes involve people’s livelihoods and psychological wellbeing.
Organizations are asking “how many AI employees can we hire in the next six months?” That framing creates exactly the mental model errors that lead to failure. The “AI employee” metaphor implies these systems are autonomous colleagues with judgment and accountability. They’re not. They’re cognitive instruments that extend human capability at specific thresholds—exactly like the “agents” I built in Discernus.
When vendors position their products as “digital workers,” “AI teammates,” and “virtual employees” who “join your workforce” and “understand your business,” they’re creating the Ghost in the Machine failure mode I documented in the Great Refactor. Organizations reasonably conclude these systems can work autonomously with minimal supervision. Then they over-delegate, the system optimizes metrics without understanding context, and catastrophic failures are sure to follow.
But there’s a second, less discussed problem: the terminology is making work psychologically toxic for the humans who remain.
Research shows that 45% of CEOs report employees are “resistant or even hostile to AI”. The standard interpretation treats this as irrational technophobia—workers simply opposing progress. But I suspect that the actual mechanism is more specific: the anthropomorphic framing forces employees into fictional social relationships that violate their intuitive understanding of what these systems are.
When Microsoft CEO Satya Nadella describes his custom agents as “AI chiefs of staff” and positions them as “just as your teammates,” or when executives announce the deployment of thousands of “AI employees,” it makes work weird in a way that’s hard to articulate but impossible to ignore. Workers know these aren’t real colleagues. They know the “digital teammate” can’t be held accountable when things go wrong. They know that when liability inevitably follows a mistake, the humans—not the “AI employees”—will bear the consequences. The psychological dissonance isn’t subtle—you’re being asked to maintain professional relationships with systems that can’t reciprocate while remaining fully accountable for their outputs.
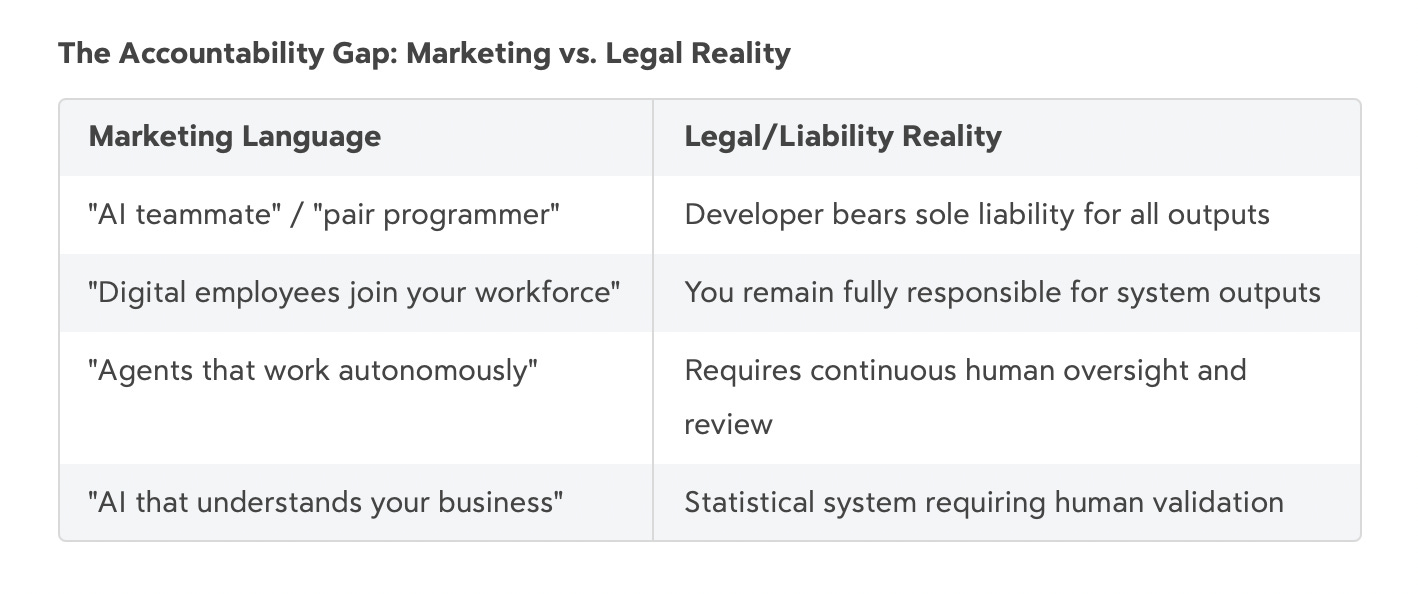
The legal cases make this pattern explicit. Air Canada marketed its chatbot as a helpful agent, then argued in tribunal proceedings that the chatbot was a “separate legal entity” responsible for its own communications when it invented policies that didn’t exist. The tribunal rejected this, holding Air Canada responsible for all website content including chatbot outputs. GitHub markets Copilot as your “pair programmer,” but their terms make clear developers bear sole liability for everything it produces. Character.AI positioned chatbots as understanding companions using relationship language, but now faces lawsuits where the central question is whether the company can be held responsible for what its AI said to vulnerable teens—a pattern that exposes the accountability gap between anthropomorphic marketing and legal reality.
Employees see this pattern. Marketing emphasizes autonomy and agency; legal defense emphasizes limitations and human responsibility. The cognitive dissonance isn’t subtle. Workers are being asked to treat statistical systems as colleagues while remaining fully accountable for their outputs. That’s not just confusing—it’s a psychological trap.
The better question organizations should be asking: “Which tasks cross delegation thresholds where cognitive instruments extend human capability, and how do we redesign jobs so humans concentrate on work they find meaningful and where accountability naturally resides?”
That reframing changes everything. You’re not replacing employees with “AI workers.” You’re redistributing cognitive labor across different substrates. The work that involves judgment, accountability, contextual interpretation, ethical reasoning, and relationship building stays with humans—that’s where meaning lives. The work that involves pattern recognition at volume, continuous attention beyond human capacity or complexity beyond human perception moves to cognitive instruments.
This is the same threshold analysis I used designing Discernus. What requires interpretation, adaptation, and accountability? That stays in my code architecture and my analytical judgment. What involves pattern matching at scale that I literally cannot do manually? That gets delegated to the LLM agents.
The parallel is exact. Software refactoring asks: what stays in deterministic code (accountability, control flow) versus what moves to cognitive instruments (interpretation, semantic processing)? Workforce refactoring asks: what stays with humans (judgment, accountability, meaning) versus what moves to cognitive instruments (scale, complexity, continuous attention)?

Both require accepting that “agents”—whether software agents or “AI employees”—lack actual agency. They can’t be held accountable. They don’t understand context. They optimize metrics without grasping goals. That’s not a limitation to overcome through better prompting. It’s a definitional reality that determines what you can safely delegate.
The Pattern: Delegation Without Accountability Transfer
Here’s the connecting insight that operates across both software and workforce refactoring:
You can delegate tasks to cognitive instruments. You cannot delegate accountability.
In software, this means your orchestration code maintains control flow and error handling while agents process at scale. When an LLM agent in Discernus produces malformed output, my code catches it. When it misinterprets an analytical framework, my validation logic flags it. The agent extends my capability; it doesn’t replace my responsibility for ensuring the system works correctly.
In workforce design, this means humans maintain accountability for outcomes while cognitive instruments handle volume or complexity beyond human capacity. When JPMorgan’s fraud detection AI flags suspicious transactions, human investigators make the final call. When Klarna’s customer service AI handles routine inquiries, humans review edge cases and provide escalation paths. The AI extends capability; it doesn’t replace accountability for customer outcomes.
Organizations fail when they misunderstand this boundary. The “AI employee” framing suggests you can transfer accountability along with tasks. You can’t. Not legally (as Air Canada and GitHub discovered), not operationally (as UnitedHealth and McDonald’s discovered), and not psychologically (as the 45% hostile-to-AI statistic reveals).
The vendors selling “autonomous AI agents” and “digital workers” know this. Their terms of service make it explicit—you remain fully responsible for outputs. But the marketing language systematically obscures this reality, creating exactly the category confusion that leads to over-delegation, catastrophic failures, and workplace dysfunction.
What To Optimize For
If you accept that the “agent” and “AI employee” terminology isn’t going away—and I think that battle is lost—the question becomes: what should these terms mean in practice?
For software teams: “Agents” should mean procedurally-contextualized cognitive instruments wrapped in orchestration code that maintains accountability. Optimize for clean separation between control flow (stays Thick) and semantic processing (goes Thin). Build assuming agents will produce probabilistic outputs requiring validation, not deterministic results you can trust blindly. Design your architecture so when an agent fails, your deterministic code catches it.
For workforce planners: “AI employees” should mean cognitive instruments that extend human capability at delegation thresholds, not autonomous workers replacing human judgment. Optimize for meaningful human work concentrated where accountability naturally resides—judgment calls, ethical reasoning, contextual interpretation, relationship building. Redesign jobs to eliminate the cognitive grunt work that overwhelms humans while preserving the parts that provide professional fulfillment and clear responsibility.
For both: Stop pretending agents have agency they lack. Call them agents if you want—the terminology probably isn’t changing. But design your systems recognizing they’re powerful pattern matchers that optimize metrics without understanding goals, predict patterns without grasping meaning, and execute procedures without recognizing context.
The Thin Software pattern works because it respects this boundary. The successful workforce integrations I documented in the Great Refactor work for the same reason. Both maintain accountability in the non-AI component while capturing the genuine advantages cognitive instruments provide at scale.
The Refactor We Actually Need
The Great Refactor is happening whether we talk about it clearly or not. Software is being rewritten around cognitive instruments. Workforces are being restructured around new task allocations. The question isn’t whether this happens—it’s whether we do it thoughtfully or stumble through it with confused mental models.
I’ve built what vendors call “agentic AI.” I understand the power. I also understand the limitations. The systems I built aren’t autonomous. They don’t have judgment. They require careful orchestration, constant validation, and clear boundaries between what they handle versus what I handle.
The same principles apply whether you’re refactoring code or refactoring teams. Identify true delegation thresholds. Maintain accountability in the component capable of bearing it. Design for sustained operation, not just initial deployment. Optimize for the long-term architecture, not the short-term demo.
And please—for the love of workplace sanity—stop telling employees their new “AI teammates” are joining the workforce. You’re deploying cognitive instruments that require human oversight. Frame them that way. Your workers will respect you more for the honesty, and you’ll avoid the psychological toxicity and over-delegation traps that the anthropomorphic framing creates.
The refactor demands precision about what these systems actually are and what they can actually do. Whether you’re writing code or redesigning jobs, that clarity determines whether you capture the genuine value or stumble into the predictable failure modes.
Call them agents if you must. Just don’t delegate accountability to systems that can’t bear it.
This analysis builds on “The Great Refactor”, which systematically examined 47 enterprise AI implementations to identify patterns of success and failure. Complete dataset and methodology available at github.com/sigma512/great-refactor-data.
© 2025 Jeff Whatcott