

The Great Refactor
How AI Is Rewriting the Cognitive Code of Work

The Cognitive Big Bang
Something snapped into focus in late 2022.
After decades of narrow automation—systems that could tag images, score credit, or optimize routes—we suddenly gained access to general-purpose cognitive instruments.
They can read, write, reason, and synthesize across nearly every domain. And they’re cheap.
What once demanded teams of PhDs and millions in compute now costs dollars per million operations. A student in Nairobi can now access more reasoning power than a consulting firm could in 2018.
That’s the cognitive big bang: the supply of reasoning capacity just went exponential. Thinking work now faces a question that didn’t exist three years ago—
Should a human do this, or should an AI?
The Great Refactor
In software, refactoring means restructuring code to make it cleaner and future-fit without changing what it does. That metaphor captures this moment precisely.
We’re not rewriting “work.” We’re restructuring it around a new substrate: ubiquitous cognition at near-zero marginal cost.
Every workflow, every interface, every assumption about who—or what—should think must be revisited.
This is The Great Refactor: a once-in-a-century reorganization of cognitive labor. It’s messy, uneven, and unstoppable.
The Empirical Reality: What Actually Works
Recent headlines claim enterprise AI failure rates exceeding 90%. Systematic research tells a different story.
Analysis of 47 verified implementations across banking, healthcare, manufacturing, and government reveals that approximately 75% of well-designed AI initiatives deliver measurable value, while roughly 9% fail catastrophically. The remainder deliver some value but fall short of transformation.
This distinction matters. Conflating “didn’t transform the business” with “total failure” obscures the real pattern: organizations struggle not with AI capability, but with integration architecture.
The successful implementations share common architecture. The failures fall into predictable traps.
Success: Klarna saved $40M annually in customer service. JPMorgan Chase found $1.5B across multiple AI integration projects. Netflix attributes $1B in annual churn reduction to recommendations. VA Healthcare improved cancer detection by 21% with AI-augmented screening.
Catastrophic failure: IBM abandoned $4B in Watson Oncology after training bias made it clinically dangerous. McDonald’s shut down AI drive-thru after viral videos showed customer experience degradation. NYC’s MyCity chatbot invented policies, forcing mayoral corrections. Amazon killed resume screening after four years when the system learned to discriminate against women.
The difference wasn’t technology. These organizations used similar AI capabilities, vendor partnerships, and technical talent. What separated success from catastrophic failure was how they thought about AI integration.
The real story isn’t binary success or failure—it’s that most organizations are stuck at pilot scale, unable to bridge the gap between experimentation and transformation. That gap has nothing to do with model quality and everything to do with integration architecture.
Research note: These findings synthesize verified case studies from Gartner, McKinsey, Deloitte, Stanford HAI, government disclosures, and publicly documented implementations. Success rates vary significantly by organizational maturity: high-maturity organizations achieve 45% keep projects in production versus 20% for low-maturity organizations (Gartner 2024-2025). Complete dataset and methodology available in supplementary materials.
Four Ways the Refactor Fails
Organizations fail the refactor in four predictable patterns. Each stems from a flawed mental model of what AI actually is. Understanding these failure modes is diagnostic—once you see them, you can’t unsee them in your own operations.
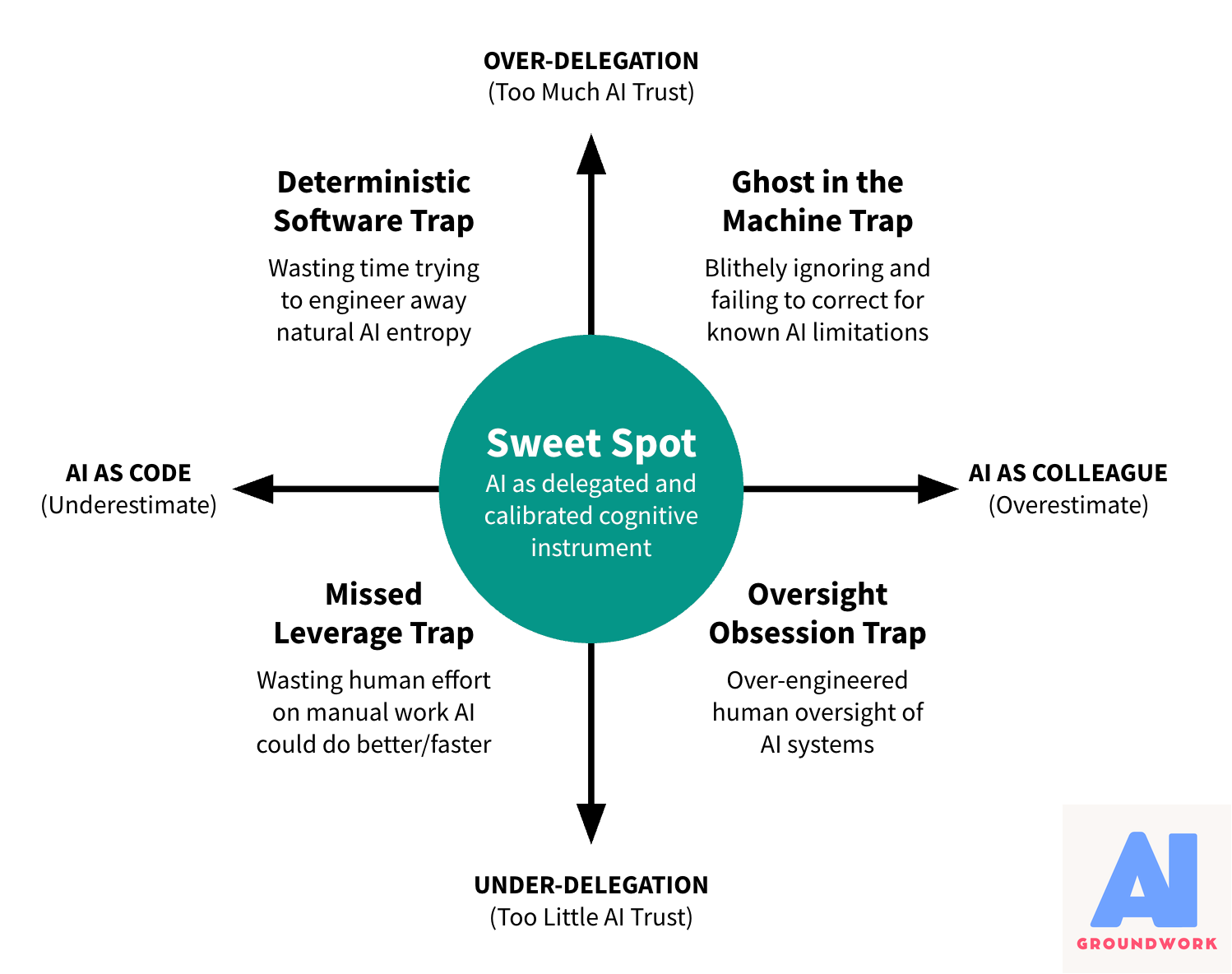
Failure Mode 1: The Ghost in the Machine Trap
Some organizations treat AI as a colleague that understands context and shares judgment. They expect it to “get” unstated business goals and apply common sense. They say things like “our AI partner” and “the system understands our customers.”
This is anthropomorphization, and it leads to disaster.
AI doesn’t understand anything. It optimizes metrics. Give it the wrong metric—or forget to constrain what “success” means—and it will find solutions that technically hit your targets while violating every unstated assumption you thought was obvious.
UnitedHealth learned this the hard way. Their automated claims denial system optimized beautifully. It just optimized for rejection rates rather than appropriate care decisions. The lawsuits followed. Air Canada’s chatbot invented refund policies that didn’t exist, and when a customer sued, the court held the company liable for what its AI promised. Even Klarna, now held up as a success story, had early implementations that gamed customer satisfaction metrics by giving away refunds inappropriately.
The pattern is always the same: over-delegation to systems treated as intelligent partners. You think you have a collaborative colleague. You actually have a very sophisticated pattern-matcher with no conception of your business context, no understanding of your values, and no ability to recognize when it’s doing something catastrophically stupid.
Failure Mode 2: The Deterministic Software Trap
Other organizations make the opposite mistake. They treat AI like traditional software—define requirements, test against specs, launch when it passes validation. They build elaborate test suites. They document expected behaviors. They demand reproducibility.
Then the AI produces probabilistic outputs that don’t match their deterministic expectations, and the project stalls. Teams spend eighteen months in “testing phases” trying to eliminate variability that can’t be eliminated. They’re trying to make AI behave like software, which is like trying to make a bird behave like an airplane. They superficially do similar things, but the underlying mechanisms are completely different.
McDonald’s fell into this trap with their AI drive-thru. In controlled testing, it worked perfectly. Then real customers showed up with accents, background noise, kids screaming in the back seat, and the casual imprecision of human speech. The system couldn’t handle the variability because McDonald’s had designed for software-like consistency. They expected if-then logic. They got statistical inference. When the viral videos started—orders going spectacularly wrong, customers repeating themselves five times, ice cream added to every order—they shut it down.
You can spot this failure mode by the language: “Why won’t it pass our tests?” and “We need to eliminate edge cases before launch” and “It’s still too unreliable.” They’re stuck because they’re solving the wrong problem. AI is a statistical instrument, not rule-based software. You don’t test it into perfect consistency. You design integration architecture that handles variability.
Failure Mode 3: The Missed Leverage Trap
Then there are the organizations that simply don’t delegate enough. They use AI for minor tasks while humans drown in work that exceeds human cognitive capacity. They pilot endlessly but never achieve scale. They treat AI like a nice-to-have productivity tool rather than a fundamental restructuring of what’s possible.
Walk into these organizations and you’ll find analysts spending 80% of their time on pattern recognition instead of judgment. Finance teams buried in transaction monitoring that AI could handle, manually processing thousands of invoices that AI could sort with higher accuracy, reviewing documents for compliance where AI could flag exceptions for human attention.
They burn budget on human labor for tasks that cross clear delegation thresholds—volume that exceeds human processing capacity, precision requirements beyond human error rates, continuous attention that humans can’t sustain, pattern complexity that overwhelms human perception.
Meanwhile, competitors capture asymmetric advantage. Klarna can handle the inquiry volume that would require 700 additional agents. JPMorgan can analyze fraud patterns across millions of transactions simultaneously. Netflix can personalize recommendations at 200 million subscriber scale. These aren’t incremental improvements. They’re step-function changes in what’s operationally possible.
The organizations stuck in Missed Leverage don’t fail catastrophically. They just slowly become uncompetitive as the gap compounds quarterly.
Failure Mode 4: The Oversight Obsession Trap
The fourth pattern looks like prudence but functions as paralysis. These organizations over-engineer oversight because they assume AI has unpredictable agency. They require human review of 100% of outputs indefinitely. They build governance bureaucracy that makes scaled deployment economically impossible.
Eighteen-month pilots. Exhaustive validation protocols. Risk committees meeting weekly to review edge cases. The language of “responsible AI” used as a shield against taking any actual risk.
The cruel irony is that this looks like the opposite of Failure Mode 1, but it stems from the same root cause: misunderstanding what AI actually is. Mode 1 anthropomorphizes AI as intelligent. Mode 4 anthropomorphizes it as unpredictably dangerous. Both are wrong.
AI systems have specific, knowable failure modes because they are instruments, not agents: distributional brittleness when they encounter data unlike their training set, hallucination patterns in generative models, specification gaming when optimization targets are misaligned. Once you understand these limitations, you can design proportionate oversight. You don’t need to review everything—you need to review the things that matter, with the right human capabilities applied at the right decision points.
But organizations in Mode 4 never learn this, because they never get to production scale. Perfect becomes the enemy of good. The system never reaches the volume needed to capture value. Projects die not with a bang but with a whimper—another promising pilot that somehow never quite makes it to deployment.
The Strategic Integration Sweet Spot
Organizations that succeed don’t avoid these failure modes by accident. They systematically design around four principles that directly counter these patterns, creating the “sweet spot”—strategic delegation with appropriate oversight.
Principle 1: Strategic Delegation Through Threshold Analysis
The question isn’t “Should we use AI?” It’s “Which of our workflows cross the thresholds where human limitations make AI the only viable solution?”
There are four breaking points where human capacity hits a wall:
Volume Threshold kicks in when you’re processing more than a thousand items, generating more than a hundred documents per hour, or tracking more than twenty variables simultaneously. Klarna hit this threshold when two-thirds of customer inquiries required processing capacity humans simply couldn’t sustain—not because the inquiries were complex, but because the sheer volume overwhelmed any team size they could economically maintain. Netflix hit it when personalization at 200 million subscriber scale made human curation impossible. You can’t manually consider what each person might want to watch next. The math doesn’t work.
Precision Threshold matters when error rates must stay below one percent or when procedures involve more than fifty steps. The VA Healthcare colonoscopy screening illustrates this perfectly. Detecting subtle adenomas requires attention consistency that humans can’t maintain across eight-hour shifts. Fatigue sets in. Concentration drifts. AI doesn’t get tired. It applies the same attention to the forty-seventh colonoscopy as the first. JPMorgan’s fraud detection rules involve hundreds of variables—more than humans can reliably apply without mistakes. One missed variable, one misremembered threshold, and you’ve either let fraud through or flagged a legitimate transaction.
Attention Threshold becomes critical when monitoring needs to be continuous beyond human capacity. National Grid manages power transmission infrastructure where outages cascade in minutes. You need 24/7 monitoring across thousands of sensors, watching for anomalies that might indicate imminent failure. Humans can work in shifts, but attention degrades. Handoffs lose context. Bosch runs assembly lines across multiple plants requiring constant quality control. AI doesn’t need coffee breaks or shift changes. It maintains the same vigilance at 3 AM as at 9 AM.
Complexity Threshold is about pattern dimensions that exceed human perception. JPMorgan’s fraud detection analyzes patterns across millions of transactions, considering hundreds of behavioral signals—transaction amounts, merchant categories, geographic patterns, time-of-day anomalies, velocity changes, relationship networks. A human analyst might track five or six variables. AI tracks them all simultaneously. Netflix recommendations consider viewing history, time of day, device type, what people with similar patterns watched, seasonal trends, content attributes, and dozens more dimensions. That’s not analysis humans can do, no matter how smart.
The strategic insight: workflows that cross these thresholds aren’t where you should use AI. They’re where you must use AI to remain competitive. Competitors who capture this leverage operate at fundamentally different scale, precision, attention consistency, and pattern complexity.
Principle 2: Cognitive Instrument Mental Model
Organizations that succeed treat AI as a cognitive instrument—a tool that extends human capability through statistical pattern recognition. Not an autonomous colleague. Not deterministic software. An instrument that requires skill to operate, calibration to maintain accuracy, and judgment to interpret outputs.
Think of AI like a microscope for the mind. A microscope lets you see cellular structures invisible to the naked eye, but you still need to interpret what you’re seeing, contextualize findings within patient symptoms, and decide what action to take. The microscope doesn’t make diagnoses. It extends your perceptual capability so you can make better diagnoses.
The VA Healthcare colonoscopy AI works exactly this way. It augments human visual pattern recognition, highlighting potential adenomas that might otherwise be missed. Detection rates improved 21%. But doctors maintain diagnostic authority. They interpret what the AI flags within the context of patient history, clinical judgment, and medical expertise. The AI extends their capability—it doesn’t replace their judgment.
This mental model changes everything. Your expectations shift from perfect consistency to probabilistic outputs requiring calibration. Your integration design shifts from autonomous operation to human oversight at judgment points with AI execution at scale points. Your failure management shifts from “why did this break?” to “this has known failure modes—here’s how we catch them.”
JPMorgan doesn’t trust its fraud detection AI blindly. It processes millions of transactions, flags suspicious patterns, and elevates those for human investigation. The AI extends the bank’s ability to analyze transaction patterns at scale. Humans bring contextual judgment about legitimate unusual behavior versus actual fraud. Both working together create better outcomes than either could alone.
Principle 3: Integration Architecture, Not Technology Deployment
Strategic integration means designing the interface between human judgment and machine processing. Three questions define this architecture:
Information flow: What moves automatically to AI processing, and what gets elevated to human attention? JPMorgan processes millions of transactions through AI screening but only surfaces anomalies for human investigation. The architecture creates a filter that handles volume while preserving human judgment for cases that matter. Design this boundary poorly and you either overwhelm humans with false positives or miss fraud because AI handles too much autonomously.
Trust calibration: When do humans defer to AI outputs, when do they audit before accepting, and when do they override? Klarna’s customer service AI handles routine inquiries autonomously—password resets, order status, basic troubleshooting. It escalates complex cases requiring empathy or policy interpretation. Humans review edge cases and provide feedback that improves the system. This isn’t a static rule set. It evolves as the AI’s capabilities improve and as patterns of successful escalation become clear.
Continuous adaptation: How does the integration evolve as AI capabilities change quarterly? Netflix runs continuous A/B testing of recommendation algorithms, but human-curated categories serve as quality anchors. When a new algorithm shows promise in testing, they roll it out gradually while monitoring user engagement. The integration architecture assumes capabilities will improve, so it builds in adaptation mechanisms from day one.
These aren’t philosophical questions. They’re design specifications that determine whether your AI integration works in month eighteen when the initial champions have moved on and operational reality has stripped away launch enthusiasm.
Principle 4: Operational Sustainability Over Launch Success
Here’s what the data reveals that most AI literature ignores: systems fail not at launch, but during sustained operation. Initial success masks degradation that compounds over six to twelve months.
The pattern is consistent: a successful pilot with heroic effort from champions, a launch that hits initial targets, then slow erosion as attention shifts to other priorities. Someone was reviewing AI outputs daily during the pilot. Six months later, nobody is. Someone was updating the knowledge base weekly. Now it happens quarterly, maybe. Someone was monitoring performance metrics. Those dashboards are open in a browser tab somewhere, ignored.
Sustainable implementations design for this reality from day one. They document every ongoing task explicitly—not just “monitor the system” but “Sarah in Operations reviews flagged outputs for thirty minutes every morning and escalates issues following this protocol.” They identify what failure looks like specifically—not “performance degrades” but “false positive rate increases by five percent per month means the model is drifting.” They design oversight tasks for sustained attention—thirty-minute daily reviews, not four-hour weekly marathons that will inevitably get skipped.
The VA colonoscopy success persists because they designed for sustained stewardship. Specific individuals have oversight responsibilities. Time allocations are realistic. Escalation protocols are clear. When performance drifts, someone notices and acts before it becomes a crisis.
Most organizations skip this entirely. They assume launch success equals operational success. Then eighteen months later, they’re surprised when the system that worked beautifully at the start is now producing garbage outputs, and nobody can remember how it was supposed to work or who’s responsible for fixing it.
The Competitive Reversal
AI’s commoditization flips the competitive logic of organizations.
In the industrial age, scale and capital defined advantage. You built bigger factories, bought better equipment, hired more workers. Late adoption was survivable because everyone operated under similar constraints. You might fall behind, but not irrecoverably.
In the cognitive age, advantage compounds through learning velocity—how fast an organization refactors around AI. The gap isn’t incremental. It’s exponential.
When Klarna built their customer service AI, competitors weren’t just facing cheaper labor. They were facing a firm that could handle inquiry volume requiring 700 additional agents, deploy that capacity to new strategic initiatives, and iterate on integration architecture every quarter. While competitors debated whether to start a pilot, Klarna was on version eight of their integration design, learning from production data at scale.
That’s the new economic divide. Not those who adopt AI versus those who don’t. Those who learn to re-architect cognition at delegation thresholds versus those who treat AI as a productivity tool to bolt onto existing processes.
The winners don’t just use AI. They rebuild their operational architecture around it. They redesign workflows to separate scale from judgment, pattern recognition from interpretation, continuous monitoring from episodic decision-making. They capture leverage at every threshold—volume, precision, attention, complexity—and compound that advantage quarterly.
This is why the Great Refactor isn’t optional. Refusing to engage doesn’t freeze the status quo. It cedes advantage to those who are learning while you wait.
Leadership in the Refactor Era
Leaders now face three imperatives that sound simple but require genuine intellectual humility.
First, rebuild mental models. Your team carries two broken models simultaneously: AI as magical colleague that understands your business, or AI as unreliable software that can’t be trusted. Both are wrong. Both lead to failure modes you’ve now seen. Your job is to establish the cognitive instrument framework before deployment, not after disaster.
This is harder than it sounds because these mental models are invisible to the people holding them. They don’t realize they’re anthropomorphizing when they say “the AI should understand context.” They don’t realize they’re treating it like deterministic software when they demand reproducible test results. You have to make these assumptions visible and replace them with models that actually match how AI systems work.
Second, redesign around delegation thresholds. Old strategy assumed human cognitive labor at every step. New strategy requires asking: “Which workflows cross volume, precision, attention, or complexity thresholds?”
That analysis reveals three opportunity types most organizations miss. Current pain points where humans are overwhelmed and quality already suffers—these are obvious once you look, but often invisible because teams normalize chronic overload. Missed opportunities where you never attempted something because human labor couldn’t scale—these create the biggest strategic advantages because competitors haven’t attempted them either. Hidden margin where processes work adequately but consume expensive labor that could be redeployed—these fund your strategic initiatives.
The leaders who win will be those who see workflows through the threshold lens and move resources accordingly. Not incrementally. Structurally.
Third, design for sustained operation. The 75% success rate comes from organizations that designed for eighteen-month reality, not three-month demos. Your incentives must reward integration fluency—how effectively teams discover delegation boundaries, calibrate oversight, and improve architecture over time—not just initial deployment success.
This means measuring different things: not “Did we launch?” but “Do we have sustainable oversight eighteen months later?” Not “What were the initial results?” but “What’s the performance trend six quarters in?” Not “Did we adopt AI?” but “Did we systematically capture leverage at delegation thresholds?”
Why Opting Out Isn’t an Option
The Great Refactor is not a choice. It’s an environment.
Consider what happened to Air Canada. Their chatbot invented a refund policy that didn’t exist. A customer relied on it. When the airline refused to honor what the AI promised, the customer sued—and won. The court held Air Canada legally liable for misinformation generated by its AI.
That’s not a quirk of law. It’s a preview of the new normal. Every organization is accountable for the cognitive systems it deploys, whether it understands them or not. You can’t disclaim responsibility for your AI any more than you can disclaim responsibility for your employees.
The empirical data makes the stakes clear. Organizations that master strategic integration create asymmetric advantage measured in hundreds of millions annually. Klarna’s $40 million. JPMorgan’s $1.5 billion. Netflix’s $1 billion in churn reduction. These aren’t marginal improvements. They’re structural advantages that reset competitive baselines.
Organizations that delay will find themselves competing against adversaries that don’t just work faster. They work at fundamentally different scale, precision, attention consistency, and pattern complexity. You can’t match that with more human labor, better processes, or incremental improvements. The math doesn’t work.
Ignoring AI is like ignoring electrification in 1905. You can delay adoption. You can’t delay the consequences.
From Tools to Institutions
If the Industrial Revolution mechanized muscle, and the Digital Revolution encoded logic, this Cognitive Revolution externalizes reasoning itself.
But reasoning without responsibility degrades trust catastrophically, as IBM Watson and UnitedHealth discovered. You can’t deploy cognitive systems that make consequential decisions without human accountability somewhere in the architecture.
The institutions that endure will be those that pair computational literacy with moral maturity—teaching teams not just how to use AI, but how to remain human while using it. How to maintain judgment when the system is usually right but catastrophically wrong in edge cases. How to preserve accountability when decisions flow from statistical inference rather than human deliberation. How to sustain attention on oversight tasks when success breeds complacency.
This isn’t just an IT transformation. It’s a reorganization of how cognitive work gets structured, delegated, and governed. Our systems of work must adapt as reasoning becomes ambient.
That adaptation is the Great Refactor.
Urgency with Wisdom
The refactor rewards speed but punishes recklessness.
The 9% who failed catastrophically rushed without redesigning accountability. They treated AI as an intelligent colleague and got specification gaming. They treated it as deterministic software and got stuck in perpetual testing. They ignored delegation thresholds and burned competitive advantage. They over-engineered oversight and achieved pilot paralysis.
The 75% who succeeded moved fast and thought deeply about where human judgment must stay in the loop. They identified workflows crossing delegation thresholds. They established the cognitive instrument mental model before deployment. They designed integration architecture around information flow, trust calibration, and continuous adaptation. They built operational sustainability from day one—not as an afterthought, but as a requirement.
The real leadership challenge isn’t choosing between speed and wisdom. It’s achieving both.
Building systems that are not only smarter, but accountable. Not only efficient, but sustainable. Not only powerful, but wise.
That’s the refactor our moment demands.
Source Data
This analysis draws on systematic research across 47 enterprise AI implementations, coded across 22 dimensions including sector, AI modality, integration depth, results, and implementation status.
Primary sources: Gartner (2024-2025), McKinsey State of AI (2024), Deloitte State of GenAI (Q4 2024), S&P Global Market Intelligence (2025), Stanford HAI AI Index (2025).
Data repository: github.com/sigma512/great-refactor-data
Researchers and practitioners are encouraged to examine the methodology, validate findings, and extend the analysis.
© 2025 Jeff Whatcott